使用Docker在本地搭建Hadoop分布式集群
本文档参考http://tashan10.com/yong-dockerda-jian-hadoopwei-fen-bu-shi-ji-qun/。
一、 Docker安装
二、构建含有Java运行环境的ubuntu镜像
1. 下载ubuntu镜像
使用如下命令从Docker仓库中获取ubuntu的最新镜像。
SimontekiMacBook-Pro:~ liu$ docker pull ubuntu
镜像下载完成后,使用命令docker images可以查看本地所有镜像。
SimontekiMacBook-Pro:~ liu$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest f49eec89601e 4 weeks ago 129 MB
SimontekiMacBook-Pro:~ liu$
2. 启动容器
下面,我们以ubuntu镜像作为基准镜像,构建包含Java运行环境的ubuntu镜像。
先使用如下命令启动一个容器:
SimontekiMacBook-Pro:~ liu$ docker run -ti ubuntu
root@52573ef1de5d:/#
可以看到容器几乎瞬间就启动起来了,比虚拟机不知快了多少倍!
3. Java安装
依次执行下面命令安装Java
root@52573ef1de5d:/# apt-get update
root@52573ef1de5d:/# apt-get install software-properties-common python-software-properties
root@52573ef1de5d:/# add-apt-repository ppa:webupd8team/java
root@52573ef1de5d:/# apt-get update
root@52573ef1de5d:/# apt-get install oracle-java7-installer
root@52573ef1de5d:/# java -version
注意:这里安装的Java7(JDK1.7),如需其他版本请自行修改apt-get install oracle-java7-installer命令,例如命令apt-get install oracle-java6-installer将安装JDK1.6
4. 保存镜像复本
现在可以将装好Java的容器保存为一个镜像副本,将来需要的时候可以在此复本基础上构建其他镜像。
先退出上面启动的容器,将上面的容器保存为镜像ubuntu:java,然后使用docker images命令,发现ubuntu:java已保存为本地镜像。
root@52573ef1de5d:/# exit
exit
SimontekiMacBook-Pro:~ liu$ docker commit -m "java install" 52573ef1de5d ubuntu:java
sha256:21716d1532e71a207cd80bcea8579e646a73d6e688ec0984562c92cdbc6296f4
SimontekiMacBook-Pro:~ liu$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu java 21716d1532e7 About a minute ago 791 MB
ubuntu latest f49eec89601e 4 weeks ago 129 MB
SimontekiMacBook-Pro:~ liu$
上面命令中52573ef1de5d为之前启动的容器的ID, ubuntu:java是为复本镜像的标识,ubuntu为仓库名,java是Tag。
如何获取容器ID:
在使用到容器的ID却不知道时,可以使用下面两个方法找到容器的ID:
- 启动容器后,命令行中用户名@后面的那一串字符时当前启动的容器的ID,因此上面启动的容器的ID为52573ef1de5d。这个方法只在容器启动并且没有指定hostname时才能用。
- 使用
docker ps列出所有正在运行的容器,在命令结果中查看对应容器的ID。
三、 构建含有Hadoop运行环境的ubuntu镜像
下面,我们以包含Java运行环境的ubuntu镜像作为基准镜像,构建包含Hadoop运行环境的ubuntu镜像。
1. 启动容器
使用刚刚已经安装了Java的容器镜像启动一个容器:
SimontekiMacBook-Pro:~ liu$ docker run -ti ubuntu:java
root@aac699216bce:/#
装有Java的ubuntu容器启动成功了,现在我们开始安装Hadoop。
这里,我们直接使用wget下载安装文件。
2. 安装wget
使用如下命令安装wget。
root@aac699216bce:/# apt-get install -y wget
3. 下载并解压安装Hadoop文件
使用如下命令下载并解压安装Hadoop。
root@aac699216bce:/# cd ~
root@aac699216bce:~# mkdir software
root@aac699216bce:~# cd software
root@aac699216bce:~/software# mkdir apache
root@aac699216bce:~/software# cd apache/
root@aac699216bce:~/software/apache# mkdir hadoop
root@aac699216bce:~/software/apache# cd hadoop/
root@aac699216bce:~/software/apache/hadoop# wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
root@aac699216bce:~/software/apache/hadoop# tar zxvf hadoop-2.6.0.tar.gz
注意:这里我们安装的Hadoop版本是2.6.0
4. 配置环境变量
由于我们使用apt-get安装java,不知道java装在什么地方,使用如下命令查看Java安装目录
root@aac699216bce:~/software/apache/hadoop# update-alternatives --config java
There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-7-oracle/jre/bin/java
Nothing to configure.
root@aac699216bce:~/software/apache/hadoop#
修改~/.bashrc文件,在文件末尾加入下面配置信息:
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export HADOOP_HOME=/root/software/apache/hadoop/hadoop-2.6.0
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
5. 配置Hadoop
下面,我们开始修改Hadoop的配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml和hadoop-env.sh。
(1) 创建目录
开始配置之前,执行下面命令,创建三个目录
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# mkdir tmp
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# cd tmp/
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0/tmp# pwd
/root/software/apache/hadoop/hadoop-2.6.0/tmp
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0/tmp# cd ..
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# mkdir namenode
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# cd namenode/
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0/namenode# pwd
/root/software/apache/hadoop/hadoop-2.6.0/namenode
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0/namenode# cd ..
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# mkdir datanode
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0# cd datanode/
root@aac699216bce:~/software/apache/hadoop/hadoop-2.6.0/datanode# pwd
/root/software/apache/hadoop/hadoop-2.6.0/datanode
- tmp:作为Hadoop的临时目录
- namenode:作为NameNode的存放目录
- datanode:作为DataNode的存放目录
(2) core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/soft/apache/hadoop/hadoop-2.6.0/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
<description>
The name of the default file system.
A URI whose scheme and authority determine the FileSystem implementation.
The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class.
The uri's authority is used to determine the host, port, etc. for a filesystem.
</description>
</property>
</configuration>
注意:
hadoop.tmp.dir配置项值即为此前命令中创建的tmp目录路径。fs.default.name配置为hdfs://master:9000,指向的是Master节点的主机(后续做集群配置时,需要配置这个节点,先写在这里)
(3) hdfs-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/software/apache/hadoop/hadoop-2.6.0/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/software/apache/hadoop/hadoop-2.6.0/datanode</value>
<final>true</final>
</property>
</configuration>
注意:
- 我们后续搭建集群环境时,将配置一个master节点和两个slave节点,所以dfs.replication配置为2。
dfs.namenode.name.dir和dfs.datanode.data.dir分别配置为之前创建的NameNode和DataNode的目录路径。
(4) mapred-site.xml配置
创建mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml配置mapref-site.xml文件
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property> </configuration>
这里只有一个配置项mapred.job.tracker,我们指向master节点机器。
(5) 修改hadoop-env.sh配置
修改如下配置:
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
6. 安装SSH
搭建集群环境,自然少不了使用SSH,这可以实现无密码访问,访问集群机器的时候很方便。
root@aac699216bce:~# apt-get install ssh
7. 生成访问密钥
root@aac699216bce:~# cd ~/
root@aac699216bce:~# ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
Generating public/private rsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
SHA256:SO6qH6zwvNUKDqVWDYcexe7OQBJ3Jy5vd/mZlF6FiWM root@aac699216bce
The key's randomart image is:
+---[RSA 2048]----+
| .. |
| . .o+ . |
| o++.+ . o |
| ..o== . E o . |
| +o+.o S o o . |
| o.o * . o o . |
|+.. O + . + + |
|.* + * = |
| B++ |
+----[SHA256]-----+
root@aac699216bce:~# cd .ssh
root@aac699216bce:~/.ssh# cat id_dsa.pub >> authorized_keys
注意: 这里思路是直接将密钥生成后写入镜像,免得在每个容器里面再单独生成一次,还要相互拷贝公钥,比较麻烦。当然这只是学习使用,实际操作时,应该不会这么搞,因为这样所有容器的密钥都是一样的!!
8. 保存镜像
我们将安装好Hadoop的镜像保存为一个镜像副本ubuntu:hadoop,然后使用docker images命令,发现ubuntu:hadoop已保存为本地镜像。
root@aac699216bce:~# exit
exit
SimontekiMacBook-Pro:~ liu$ docker commit -m "hadoop install" aac699216bce ubuntu:hadoop
sha256:b6c13157056ff28c5b8703991bd1c4ba993bc7a3fae17547bff82eedae571529
SimontekiMacBook-Pro:~ liu$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu hadoop b6c13157056f 18 seconds ago 1.35 GB
ubuntu java 21716d1532e7 About an hour ago 791 MB
ubuntu latest f49eec89601e 4 weeks ago 129 MB
四、 搭建Hadoop分布式集群
按照hadoop集群的基本要求,集群中至少需要有3个结点,其中一个为master结点,主要是用于运行hadoop集群中的namenode、secondorynamenode和jobtracker(新版本名字变了)任务;另外两个结点均为slave结点,其中一个节点作为冗余节点。
1. 启动容器
打开三个命令行,每个命令行各启动一个容器,其中一个容器作为master节点,另外两个容器作为slave节点。
####(1)启动master容器
SimontekiMacBook-Pro:~ liu$ docker run -ti -d -p 50070:50070 -h master ubuntu:hadoop
d13443e6f6e3575beee69e9cc51f0569067dc0b96fb24a756578aa610ce3310c
这里使用镜像创建容器时,将容器的50070端口映射为本地的50070端口,便于后面可以直接在本地浏览器访问集群的状态。
使用docker ps查看启动的master容器对应的ID,然后使用下面命令进入master容器。
SimontekiMacBook-Pro:~ liu$ docker attach d13443e6f6e3
root@master:/#
(2)启动slave1容器
SimontekiMacBook-Pro:~ liu$ docker run -ti -h slave1 ubuntu:hadoop
Missing privilege separation directory: /var/run/sshd
root@slave1:/#
(3)启动slave2容器
SimontekiMacBook-Pro:~ liu$ docker run -ti -h slave2 ubuntu:hadoop
Missing privilege separation directory: /var/run/sshd
root@slave2:/#
2. 配置hosts
(1)查看各节点ip
由于在不同的网络环境下,容器获取的ip可能不一样,例如本机三个容器获取的ip分别如下:
- master: 172.17.0.2
- slave1: 172.17.0.3
- slave2: 172.17.0.4
(2)修改各节点的hosts文件
根据(1)中查看得到的各节点ip配置hosts文件
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
(3)配置slaves
下面配置哪些节点是slave。
较老版本的Hadoop中有一个masters文件和一个slaves文件,但新版本中只有slaves文件了。
在master节点容器中执行如下命令打开slaves配置文件:
root@master:~/software/apache/hadoop/hadoop-2.6.0/etc/hadoop# vim slaves
将所有slave节点的hostname写入该文件:
slave1
slave2
3. 启动Hadoop
(1)启动SSH服务
在每个节点上之下下面命令,启动SSH服务,实现无密码访问。
master节点
root@master:~/software/apache/hadoop/hadoop-2.6.0/etc/hadoop# /etc/init.d/ssh start * Starting OpenBSD Secure Shell server sshd [ OK ] root@master:~/software/apache/hadoop/hadoop-2.6.0/etc/hadoop#slave1节点
root@slave1:~# /etc/init.d/ssh start * Starting OpenBSD Secure Shell server sshd [ OK ] root@slave1:~#slave2节点
root@slave2:~# /etc/init.d/ssh start * Starting OpenBSD Secure Shell server sshd [ OK ] root@slave2:~#
(2)格式化 namenode
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hadoop namenode -format
(3)启动hadoop
在master节点上执行start-all.sh命令,启动Hadoop
root@master:~/software/apache/hadoop/hadoop-2.6.0/sbin# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
slave2: starting datanode, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/yarn--resourcemanager-master.out
slave1: starting nodemanager, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /root/software/apache/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave2.out
root@master:~/software/apache/hadoop/hadoop-2.6.0/sbin#
如果看到如下信息,则说明启动成功了。
在个节点上执行jps命令,结果如下:
master节点
root@master:~/software/apache/hadoop/hadoop-2.6.0/sbin# jps 2149 Jps 1887 ResourceManager 1560 NameNode 1736 SecondaryNameNode root@master:~/software/apache/hadoop/hadoop-2.6.0/sbin#slave1节点
root@slave1:~# jps 352 DataNode 454 NodeManager 569 Jpsslave2节点
root@slave2:~# jps 252 DataNode 354 NodeManager 469 Jps
下面,我们在master节点上通过命令hdfs dfsadmin -report查看DataNode是否正常启动
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hdfs dfsadmin -report
Configured Capacity: 134743154688 (125.49 GB)
Present Capacity: 117625421824 (109.55 GB)
DFS Remaining: 117625372672 (109.55 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 172.17.0.4:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 67371577344 (62.74 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 8558866432 (7.97 GB)
DFS Remaining: 58812686336 (54.77 GB)
DFS Used%: 0.00%
DFS Remaining%: 87.30%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Feb 22 12:58:22 UTC 2017
Name: 172.17.0.3:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 67371577344 (62.74 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 8558866432 (7.97 GB)
DFS Remaining: 58812686336 (54.77 GB)
DFS Used%: 0.00%
DFS Remaining%: 87.30%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Feb 22 12:58:22 UTC 2017
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin#
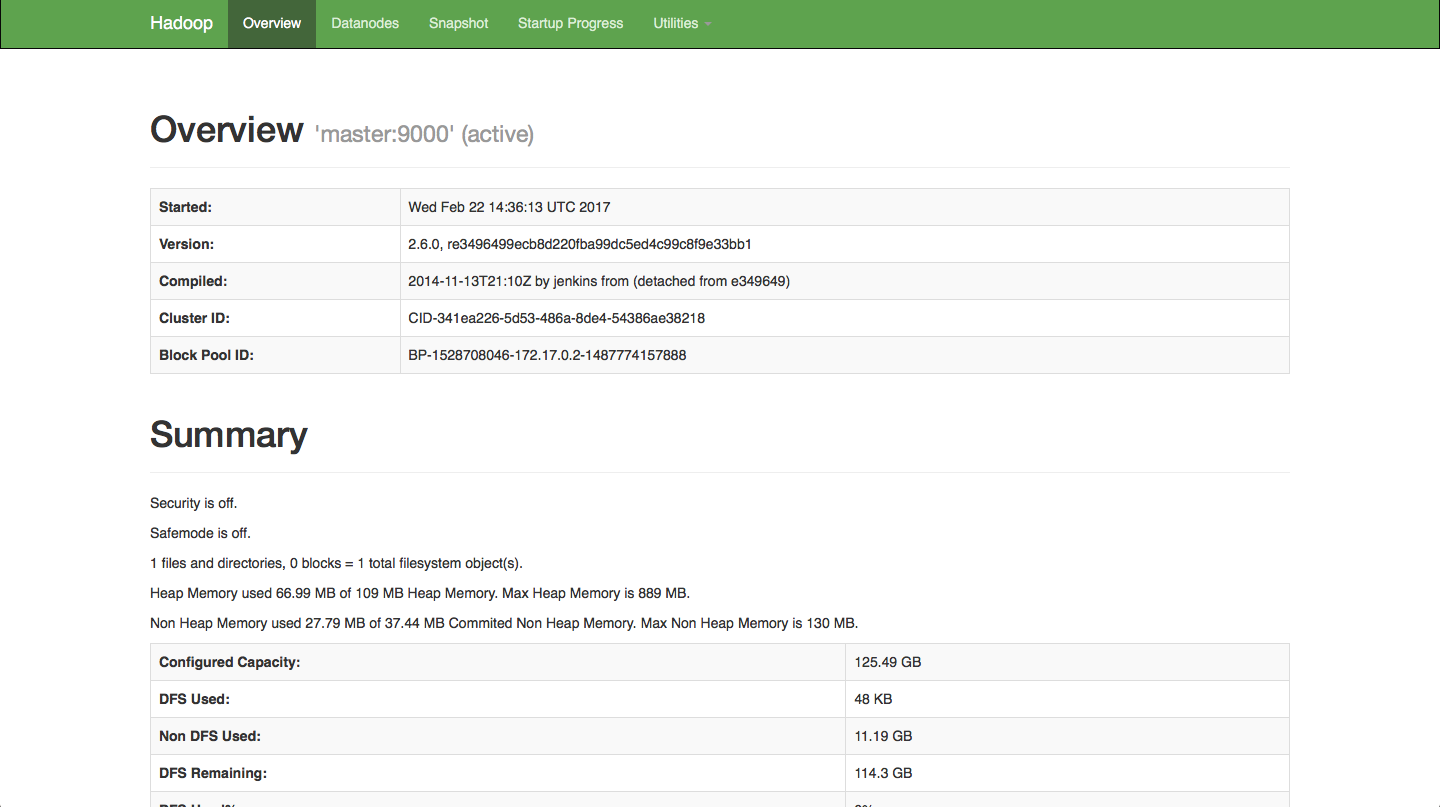
还可以通过Web页面http://127.0.0.1:50070/看到查看DataNode和NameNode的状态。
4. WordCount实例
(1) 创建本地单词文件words.txt
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# touch words.txt
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin#
在words.txt文件中写入单词。
(2)将单词文件words.txt上传到到hdfs上
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hdfs dfs -ls /
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hdfs dfs -put words.txt /
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hdfs dfs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 1763 2017-02-22 14:42 /words.txt
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin#
(3) 执行wordcount程序
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hadoop jar ../share/ hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /words.txt /out
(4) 查看结果
root@master:~/software/apache/hadoop/hadoop-2.6.0/bin# ./hdfs dfs -text /out/part-r-00000